Customer stories | Pharmaceutical | Contract processing
How a pharmaceutical company improved their productivity by automating their document processing and uploading.
Misra Ngonga | September 10, 2023 | 7 mins read

The challenge:
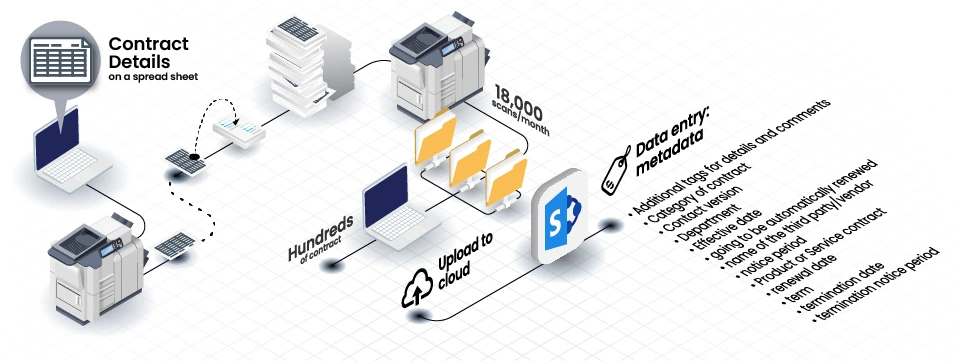
Each month, the company has to scan 18,000 times to process hundreds of contracts. The team has to fill up various info related to the contracts twice, firstly, on the hard copy and then filling in all the metadata when they uploaded to SharePoint.
The info required includes the category of contract, the name of the third party/vendor, effective date, term, renewal date, termination date, department, contract types, notice period, contract version and tags for details and comments.
What makes it even more challenging is that the scanned contracts are digital image files (in TIFF format) and are not searchable.
The solution:
Automatic document processing and upload in bulk.
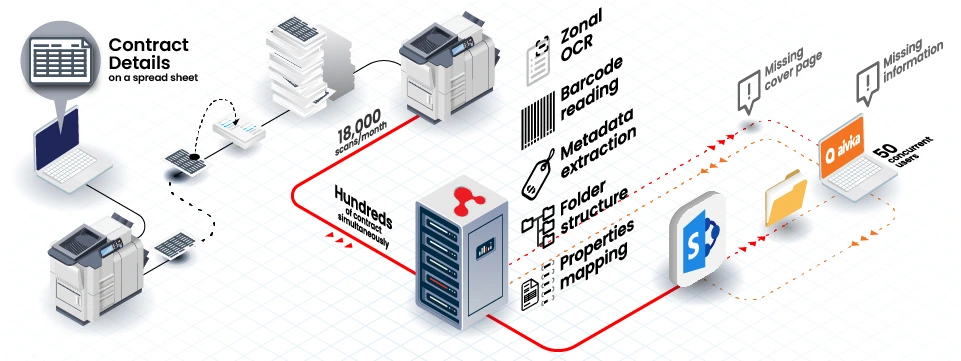
The scanned documents are converted to searchable PDFs automatically. After that, ScannerVision™ will recognize fields on the contract cover pages and extract the respective data with ZoneOCR. Lastly, through the SharePoint connector, the processed documents are uploaded to SharePoint and all the metadata are mapped to the document property fields accordingly.
If the given condition/format is not met, the documents will be uploaded to a different folder where users will review them and fill in the missing info using aivika Capture.
Contracts needed to be filed in SharePoint with correct definition by the customer like category of contract, name of the third party/vendor, effective date, term, renewal date, termination date, Department, whether it was a Product or Service contract, notice period, whether this contract was going to be automatically renewed, termination notice period and contact version. In addition to the above, the contracts could each have up to 9 additional tags for details and comments. It was important that the documents be uploaded as searchable PDF files as this would allow them to search for any keyword in any of the uploaded contracts.
The customer had all the above-mentioned fields on an Excel spreadsheet, where the person working with contract would fill in the relevant info in the fields, print the filled-out spreadsheet and use this page as the cover page of its related contract. The contract would then be scanned back with the page from the spreadsheet as one document.
Now with scanned contract as a digital image file from the scan (in TIFF format), an employee would manually upload them to SharePoint, when the document is in SharePoint, they would right-click on it to reveal the document's properties and manually enter the metadata they had previously filled out in the Excel spreadsheet.
This created a huge challenge for them as they had hundreds of contracts to upload and it was not ideal to do this whole process one contract at a time, and most importantly, the contracts were uploaded as image documents and were not searchable.
Manual Data Entry Challenges
The company grappled with a laborious manual data entry process as they scanned 18,000 contracts monthly. The team faced duplicative efforts, entering metadata both on hard copies and during the upload to SharePoint. Information such as contract category, third-party/vendor names, dates, terms, department details, contract types, notice periods, versions, and tags required meticulous manual input, leading to time consumption and potential errors.
Non-Searchable Scanned Contracts
Compounding the challenge was the scanned contracts' format – digital images in TIFF. The absence of searchable text hampered efficient retrieval and data access. Traditional search functionalities were rendered ineffective, making it difficult for the team to quickly locate and extract specific information from the contracts. The limitations in leveraging modern search capabilities intensified inefficiencies in the contract processing workflow, impeding timely access to critical data.
The Solution
ScannerVision™ - Automatic Document Processing and Upload
Barcode Reading and ScannerVision™
Using ZoneOCR in ScannerVision™, we were able to recognize the fields on the contract cover pages and extract their respective data. Using ScannerVision™ functions on the data returned by ZoneOCR we were to precisely extract only the data needed. Thanks to ScannerVision™ functions we didn't have to create multiple zones to capture from the multiple fields. One large Zone was all we needed, the functions determined which information in the zones could be extracted and where it would be used in order for it to be pushed to the appropriate Property in SharePoint.
There were multiple benefits to using one large Zone and ScannerVision™ functions to extract the needed data:
- Where the cover pages were scanned, they didn't have to be scanned 100% upright or correctly in order for the data areas on the scanned cover page to line up with the Zones in ScannerVision™ OCR engine. Using a large Zone allowed us to capture the data even when the cover page was skewed when scanned.
- The client was able to add additional fields to the cover page and this was still covered by the large zone. No additional work was needed on the ZoneOCR side of ScannerVision™ in order to capture from the newly added properties.
- Because some of the data in the cover page was manually typed by someone, there would sometimes when the same data with slight variations which would affect categorization when the data was uploaded to SharePoint. For example in the Department field, some users would enter “IT” and some would enter “IT Department”, this would incorrectly be categorised as two different departments in SharePoint. Using ScannerVision™ Functions, we were able to account for these kind of input differences without needing the users to change how they entered the info.
ScannerVision™ - SharePoint Connector
The ScannerVision™ - SharePoint connector enables us to upload documents straight to SharePoint after ScannerVision™ has processed them. After being signed in on SharePoint through the connector, the folder structure and Document properties created in SharePoint are pulled through to ScannerVision™, allowing mapping of Document and related metadata according to SharePoint in ScannerVision™.
Using the Connector, we were able to map their Coversheet metadata extracted using ZoneOCR and ScannerVision™ functions to the SharePoint document property fields.
We also used the data extracted using ZoneOCR and ScannerVision™ functions to rename the uploaded document, and to create folder structures where needed.
ScannerVision™ conditions
In addition to using functions to extract the desired data format, ScannerVision™’s function editor (expression) is able to detect when a given format or expression is not met and informs the ScannerVision™ processing engine. Using this information, we were able to use conditions to differentiate documents that had all the required info from the ones missing some key data on the cover pages.
We use conditions to upload the documents having all required information to the final storing location in SharePoint, and the ones that were missing key required info were uploaded to a different folder in SharePoint where users would review them and fill in the missing info using aivika Capture (Explained below)
Multiple Document processors
Because the client was uploading a large number of documents, we enabled multiple document processors. Each document processor works independently, this enabled ScannerVision™ to process multiple documents simultaneously.
aivika - Working with documents marked for review
aivika Capture was used to upload the document uploaded to the review folder (mentioned above). Because of the large number of documents being uploaded, the client had over 50 people working to review the document with missing info.
Questions and picklists
Since the review documents were missing information, we had template questions set up in ScannerVision™ where users could manually enter missing information which ScannerVision™ would use as document properties when uploading to SharePoint.
Document composition and aivika Printer driver
The client also had soft copy contracts that had no cover pages, they could not be stored to SharePoint correctly since the cover pages contained all the crucial contract information.
Users were able to add cover pages to these documents by filling in the info on the spreadsheet cover template, using the aivika Printer driver, they simply hit CTRL+P and chose aivika as the printer. The cover page would then be printed to the aivika interface from here they used Document composition to prepend this cover page as the first page of the contract and send it to ScannerVision™ for processing and uploading.
aivika User concurrency
Because the customer had just a little over 50 people using aivika, they only purchased 50 aivika users, since aivika offers user concurrency, we installed aivika on more than 50 machines, they could simply have up to 50 users logged in on aivika on PCs simultaneously. They had more than 50 PC users sharing the 50 aivika user slots.
The outcome
By integrating ScannerVision™ into their workflow, the Pharmaceutical company is able to improve the productivity of their team.
- The client was able to do backstamping of hundreds of contracts and have ScannerVision™ automatically and seamlessly upload them to SharePoint, to the right directories with the correct contract metadata.
- The client didn’t have to worry about contracts missing key metadata/properties as ScannerVision™ detected these and sent them to the review folder where they were reviewed by employees using aivika Capture.
- Documents that were scanned skewed or in the incorrect orientation were easily handled by ScannerVision™’s large ZoneOCR + functions, image de-skewing and automatic document orientation.
- Thanks to the combination of a large ZoneOCR and ScannerVision™ functions, the user was able to scan their contract properties from 12 to 22 without needing a workflow redesign.
Ready to reinvent your workflow? Contact our team.
You may also like:

Customer stories | Banking
How a European bank increases their Team's productivity by automating workflows and uploading documents to cloud directly.
10/09/2023 - Misra Ngonga
Learn more ➔
Customer stories | Agriculture
How a client in France improved their efficiency by automating their document capture workflow to dynamic destinations.
10/09/2023 - Misra Ngonga
Learn more ➔
Customer stories | Logistics
Enhanced Efficiency in Logistics Document Processing.
10/09/2023 - Brian Young
Learn more ➔Start building your
automated workflows.
Curious how ScannerVision™ can help you? Contact us.
Contact sales